|
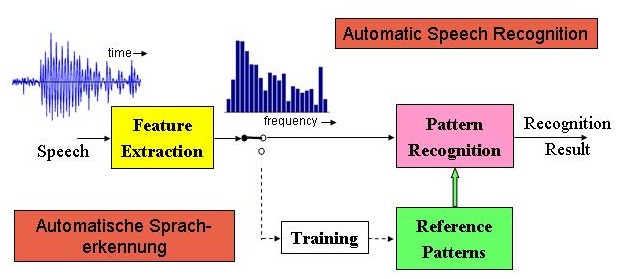
Das Ziel der automatischen Spracherkennung ist die Erkennung bestimmter Inhalte eines Sprachsignals durch eine Extraktion relevanter akustischer Merkmale aus dem Sprachsignal. Die extrahierten Merkmale werden mit den in Referenzmustern hinterlegten Merkmalen verglichen, wobei die in einem Referenzmuster enthaltenen Merkmale in einer vorausgehenden Trainingsphase bestimmt werden. Aus dem Referenzmuster, dessen Merkmale den aus dem Sprachsignal extrahierten am ähnlichsten sind, kann auf den erkannten Inhalt, beispielsweise nur ein Wort im Fall einer Erkennung von Kommandowörtern, geschlossen werden. index.php?option=com_content&view=
Die eigenen Arbeiten konzentrieren sich auf das Arbeitsgebiet der "robusten" Spracherkennung. Die Leistungsfähigkeit von Spracherkennungssystemen verschlechtert sich beispielsweise deutlich bei Vorhandensein von Hintergrundstörungen oder einer Veränderung der Frequenzcharakteristik des Sprachsignals durch den Frequenzgang eines Mikrofons oder eines Übertragungskanals.
Es gibt verschiedene Ansätze zur Erhöhung der Robustheit eines Erkennungssystems. Die am häufigsten verwendeten sind:
1. die Extraktion robuster akustischer Merkmale
2. die Adaption der Referenzmuster auf die aktuelle akustische Umgebung
Ein Beispiel für eine Sprachanalyse zur Extraktion robuster akustischer Merkmale ist ein von ETSI (European Telecommunications Standards Institute) im Jahr 2002 standardisiertes Verfahren. Dabei handelt es sich um eine auf einer Cepstralanalyse beruhende Verarbeitung des Sprachsignals, die um zwei weitere Verarbeitungsblöcke zur Gewinnung robuster Merkmale bei Vorhandensein von Hintergundstörungen und von Frequenzgangveränderungen erweitert wurde. Die zusätzlichen Verarbeitungsblöcke beinhalten eine Wiener Filterung des Sprachsignals sowie eine blinde Schätzung und Kompensation des Frequenzgangs. Eine exakte, algorithmische Beschreibung mit einer exemplarischen Realisierung in Form von C Code findet man bei ETSI unter Angabe der Kurzbezeichnung des Standards "ES 202212".
Im Rahmen eigener Arbeiten ist ein Spracherkennungsverfahren entwickelt und aufgebaut worden, bei dem die in den Referenzmustern enthaltenen spektralen Merkmale auf die jeweilige akustische Umgebung bei der Spracheingabe adaptiert werden. Dazu werden das Störspektrum als auch eine Frequenzgangveränderung bei jeder Spracheingabe neu geschätzt. Eine Veröffentlichung, in der das Verfahren detailliert beschrieben wird, kann hier eingesehen werden.
Bearbeitete und laufende Projekte
- Im Zeitraum von April 2004 bis Juni 2008 wurde im Rahmen eines von der DFG (deutschen Forschungsgemeinschaft) geförderten Projekts Untersuchungen zur robusten Spracherkennung angestellt ==> Vorstellung des Projekts
- Weitergehende Untersuchungen zur robusten Spracherkennung werden seit Juli 2008 in einem vom BMBF (Bundesministerium für Bildung und Forschung) im Rahmen des Förderprogramms FHProfUnt geförderten Projekts durchgeführt ==> Vorstellung des Projekts
- Des Weiteren werden seit September 2009 Untersuchungen zur praktischen Anwendung der Spracherkennung im Rahmen eines hochschulintern geförderten Projekts angestellt. Dabei wird das Ziel der Verbesserung einer Bedienung von Automaten, z.B. eines Fahrkartenautomaten oder eines Parkhaussystems, verfolgt ==> Vorstellung des Projekts
|

